一、进阶py:通关一个某校的题库
第一关,除去列表中的重复元素
已知两个列表,可能包含有相同元素,请找出两个列表的相同元素,并放入新的列表。打印新列表。输出结果中没有重复元素,如果两个列表中没有相同元素则输出[]。
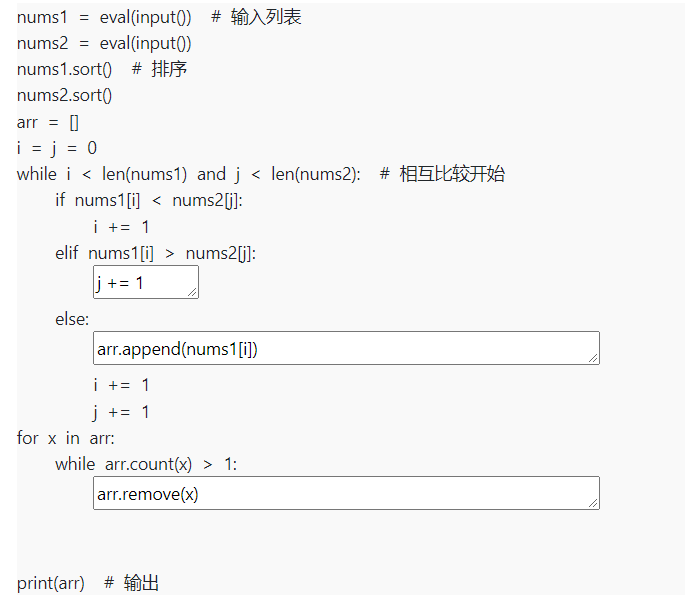
第二关 递归求嵌套层数

list_max = []
def level(mylist,a=-1):
if isinstance(mylist,list): #判断mylist变量是否是一个列表
a += 1
for item in mylist:
level(item,a)
list_max.append(a)
list_max.sort(reverse=True)
max_level = list_max[0]
return max_level + 1
else: # 不是列表,递归结束条件
return 0
origin=eval(input())
print(level(origin))
中途插一关 递归输出索引

def main():
somestr, substr, startstr, endstr = input().split()
startnum = int(startstr)
endnum = int(endstr)
fun(somestr, substr, startnum, endnum)
num_list = []
def fun(a,b,c,d):
a_list = list(a)
b_list = list(b)
if c+2<d:
if a_list[c] == b_list[0] and a_list[c+1] == b_list[1] and a_list[c+2] == b_list[2]:
index = c
num_list.append(index)
fun(a,b,c+3,d)
else:
fun(a,b,c+1,d)
else:
if num_list == []:
print(None)
else:
print(num_list)
main()
第三关 递归求加权和

num_list = []
#定义了一个吧列表里面所有元素加起来的函数
def jia(a,b=0):
for item in a:
b = b + item
return b
def sumlist(lists,w):
for item in lists:
if isinstance(item,list):
sumlist(item,w+1)
else:
num_list.append(item*w)
return jia(num_list)
nums = eval(input())
addv = sumlist(nums,1)
print(addv)
第四关

第一个correct.in文件
rhe+[35(fjej)w-wr3f[efe{feofds}]
__main__文件
#创建两个符号表
symbols = {'}': '{', ']': '[', ')': '(', '>': '<'}
symbols_l, symbols_r = symbols.values(), symbols.keys()
def check(s):
arr = []
for c in s:
if c in symbols_l:
# 左符号存入列表
arr.append(c)
elif c in symbols_r:
# 右符号要不在列表中不存在,要么匹配失败
if arr and arr[-1] == symbols[c]:
arr.pop()
else:
return False
return True
#上面用栈的思想
with open('correct.in',mode='r',encoding='utf-8') as f:
data = f.read()
res = check(data)
with open('correct.out',mode='wt',encoding='utf-8') as g:
g.write(str(res))
第五关 输出特定节日(类似母亲节)

import datetime
import calendar
data = input()
data_list = data.split(",")
a,b,c,y1,y2 = data_list
def is_valid_date(a,b,c):
#判断是否是一个有效的日期字符串
try:
datetime.date(a,b,c)
return True
except:
return False
def festival(a=a,b=b,c=c,y1=y1,y2=y2):
year = []
a = int(a)
b = int(b)
c = int(c)
y1 = int(y1)
y2 = int(y2)
for i in range(y1,y2+1):
year.append(i)
for item in year:
daterange = calendar.monthrange(item, a)
date = (b - 1) * 7 + c - daterange[0] # 计算日期
if is_valid_date(item, a, date): # 判断是否有效
print(f"{item} {a} {date}")
else:
print(None)
festival()
第六题 定义类计算票价

from datetime import date
class calculator:
def __init__(self,adult,child,date):
self.adult = adult
self.child = child
self.date_list = date.split("-")
self.year = self.date_list[0]
self.month = self.date_list[1]
self.day = self.date_list[2]
self.workday = [0,1,2,3,4]
def adult_cost(self):
x = date(int(self.year), int(self.month), int(self.day))
if x.weekday() in self.workday:
return self.adult*100
else:
return self.adult*120
def child_cost(self):
x = date(int(self.year), int(self.month), int(self.day))
if x.weekday() in self.workday:
return self.child*50
else:
return self.child*60
def isweekend(self):
x = date(int(self.year), int(self.month), int(self.day))
if x.weekday() in self.workday:
return False
else:
return True
def result(self):
a = f"adult:{self.adult},child:{self.child},isWeekend:{self.isweekend()},total cost:{int(self.child_cost()+self.adult_cost())}.0"
return a
data = input()
a,b,c = data.split(',')
ex = calculator(adult=int(a),child=int(b),date=c)
print(ex.result())
人民币大写

import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
sys.stdin = io.TextIOWrapper(sys.stdin.buffer,encoding='utf-8')
from decimal import Decimal
def cncurrency(value, capital=True, prefix=False, classical=None):
if classical is None:
classical = True if capital else False
if prefix is True:
prefix = '人民币'
else:
prefix = ''
if capital:
num = ('零', '壹', '贰', '叁', '肆', '伍', '陆', '柒', '捌', '玖')
iunit = [None, '拾', '佰', '仟', '万', '拾', '佰', '仟','亿', '拾', '佰', '仟', '万', '拾', '佰', '仟']
else:
num = ('〇', '一', '二', '三', '四', '五', '六', '七', '八', '九')
iunit = [None, '十', '百', '千', '万', '十', '百', '千','亿', '十', '百', '千', '万', '十', '百', '千']
if classical:
iunit[0] = '元' if classical else '圆'
if not isinstance(value, Decimal):
value = Decimal(value).quantize(Decimal('0.01'))
# 转化为字符串
s = str(value)
istr, dstr = s.split('.')
istr = istr[::-1]
so = [] # 用于记录转换结果
# 零
if value == 0:
return prefix + num[0] + iunit[0]
haszero = False
if dstr == '00':
haszero = True
# 处理整数部分
for i, n in enumerate(istr):
n = int(n)
if i % 4 == 0:
if i == 8 and so[-1] == iunit[4]:
so.pop()
so.append(iunit[i])
if n == 0:
if not haszero:
so.insert(-1, num[0])
haszero = True
else:
so.append(num[n])
haszero = False
else:
if n != 0:
so.append(iunit[i])
so.append(num[n])
haszero = False
else:
if not haszero:
so.append(num[0])
haszero = True
so.append(prefix)
so.reverse()
return ''.join(so)
i=input()
print (cncurrency(i)+"整")
计算教学周

import datetime
frist_date = input().split(' ')
date = input().split(' ')
year1,month1,day1 = frist_date
year2,month2,day2 = date
d1 = datetime.date(int(year1),int(month1),int(day1))
d2 = datetime.date(int(year2),int(month2),int(day2))
gap = (d2-d1).days
week = (gap-(gap%7))/7+1
xingqiji = gap%7+1
print(f"{round(week)} {xingqiji}")#用四舍五入来取整
找出同一周上课的周次

data1 = input().split(',')
data2 = input().split(',')
date1 = set()#第一节课的数据
date2 = set()#第二节课的数据
for item in data1:
if '-' in item:
gap = item.split('-')
for num in range(int(gap[0]),int(gap[1])+1):
date1.add(int(num))
else:
date1.add(int(item))
for item in data2:
if '-' in item:
gap = item.split('-')
for num in range(int(gap[0]),int(gap[1])+1):
date2.add(int(num))
else:
date2.add(int(item))
res = date1&date2
res2 = list(res)
if res == set():
print("none")
else:
final = " ".join('%s' %item for item in res2)
print(final)
课程表调表

from itertools import groupby
data1 = input().split(',')
data2 = input()
data3 = input()
date1 = []#第一节课的数据
new_date = []
def list_str(list):
final_list = []
fun = lambda x: x[1]-x[0]
for k, g in groupby(enumerate(list), fun):
l1 = [j for i, j in g] # 连续数字的列表
if len(l1) > 1:
scop = str(min(l1)) + '-' + str(max(l1)) # 将连续数字范围用"-"连接
final_list.append(scop)
else:
scop = l1[0]
final_list.append(scop)
return final_list
for item in data1:
if '-' in item:
gap = item.split('-')
for num in range(int(gap[0]),int(gap[1])+1):
date1.append(int(num))
else:
date1.append(int(item))
if int(data2) not in date1 or int(data3) in date1:
print("not available")
else:
date1.remove(int(data2))
date1.append(int(data3))
date1.sort()
xinde = list_str(date1)
result = ','.join(f'{id}' for id in xinde)
print(result)
在列表中找出有相同度的最小连续子列表,输出其长度

da = input()
data = da.replace("[","").replace("]","").replace(' ',"").split(",")
oc_list = dict()
#z把元素出现的次数输入到字典中
for item in data:
oc_list.update({f"{item}":0})
for item in data:
oc_list[f"{item}"] += 1
#j找到所有的出现次数最大的值
maxitem_buffer = max(oc_list,key=oc_list.get)
maxitem = []
for key,value in oc_list.items():
if value == oc_list.get(maxitem_buffer):
maxitem.append(key)
#找到出现次数最大的元素的起始位置和最终位置
index_buffer = []
list_buffer = []
for item in maxitem:
list_buffer.clear()
for index,it in enumerate(data):
if int(it) == int(item):
list_buffer.append(index)
index_buffer.append(list_buffer)
#计算最短的长度
len_buffer = []
for item in index_buffer:
len_buffer.append(max(item)-min(item)+1)
print(min(len_buffer))
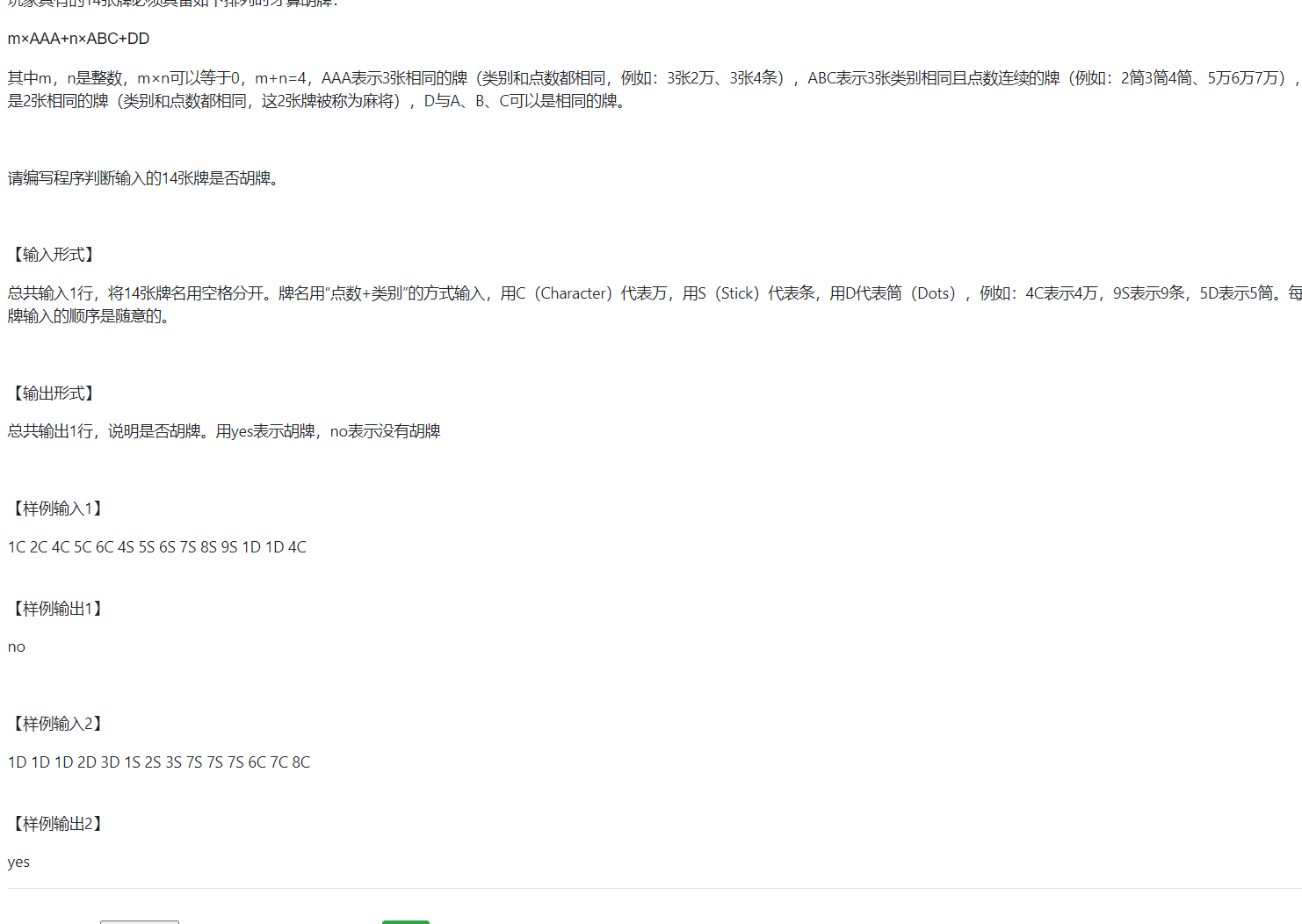
判断麻将是否胡牌
笑死我了,我写了他妈一百多行代码,以后老板看到不把我骂死
try:
data = input()
data_list = data.split(' ')
def nitian(data_list):
#把他们全部放到c d s列表中
c_list = []
d_list = []
s_list = []
for item in data_list:
if item.endswith('D'):
d_list.append(item)
elif item.endswith('S'):
s_list.append(item)
else:
c_list.append(item)
#要先找到连续的排再找到相同的排最后找做将的牌
#定义一个找连续牌的函数,返回的是元组,第一个是n第二个是减去重复元素之后的列表
def find_rconsecutive_data(listx):
item_buffer = []
result = 0
for indexs,itemx in enumerate(listx):
if len(item_buffer) == 3:
result += 1
for i in item_buffer:
listx.remove(i)
item_buffer.clear()
item_buffer.clear()
listx.sort()
item_buffer.append(itemx)
for index,item in enumerate(listx):
if len(item_buffer) >= 3:
break
elif int(list(item)[0]) - int(list(item_buffer[-1])[0]) == 1:
item_buffer.append(item)
for indexs,itemx in enumerate(listx):
if len(item_buffer) == 3:
result += 1
for i in item_buffer:
listx.remove(str(i))
item_buffer.clear()
item_buffer.clear()
listx.sort()
item_buffer.append(itemx)
for index,item in enumerate(listx):
if len(item_buffer) >= 3:
break
elif int(list(item)[0]) - int(list(item_buffer[-1])[0]) == 1:
item_buffer.append(item)
return result,listx
c = find_rconsecutive_data(c_list)
s = find_rconsecutive_data(s_list)
d = find_rconsecutive_data(d_list)
##重置所有东西,开始检测三个相同类型的牌
new_data = c[1]+s[1]+d[1]
n = int(c[0]) + int(s[0]) + int(d[0])
c_list = []
d_list = []
s_list = []
for item in new_data:
if item.endswith('D'):
d_list.append(item)
elif item.endswith('S'):
s_list.append(item)
else:
c_list.append(item)
#定义一个函数检测列表中是不是有相同的牌,返回数字和删除相同元素之后的列表
def find_repeat_data(listx):
buffer = []
result = 0
for indexs,items in enumerate(listx):
if len(buffer) >= 3:
result += 1
for itemxxx in buffer:
listx.remove(itemxxx)
buffer.clear()
buffer.clear()
buffer.append(items)
for index,item in enumerate(listx):
if index == indexs:
pass
elif len(buffer) >= 3:
break
elif item == buffer[-1]:
buffer.append(item)
for indexs,items in enumerate(listx):
if len(buffer) >= 3:
result += 1
for itemxxx in buffer:
listx.remove(itemxxx)
buffer.clear()
buffer.clear()
buffer.append(items)
for index,item in enumerate(listx):
if index == indexs:
pass
elif len(buffer) >= 3:
break
elif item == buffer[-1]:
buffer.append(item)
return result,listx
#再次重置东西,进行最后的做将判断
s = find_repeat_data(s_list)
c = find_repeat_data(c_list)
d = find_repeat_data(d_list)
DATA = s[1]+c[1]+d[1]
n += s[0]+c[0]+d[0]
if n >= 4 and len(DATA) == 0:
return "yes"
else:
return "no"
def zuojiang(data_list):
repeat = []
for indexx,itemx in enumerate(data_list):
if len(repeat) == 2:
for re in repeat:
data_list.remove(re)
repeat.clear()
return data_list
repeat.clear()
repeat.append(itemx)
for index,item in enumerate(data_list):
if index == indexx:
pass
elif item == repeat[-1]:
repeat.append(item)
break
return data_list
#做不同的将,但凡有一个yes,那么我们就成功了
result = []
for i in range(len(data_list)):
data_listx = [item for item in data_list]
if i == 0:
result.append(nitian(zuojiang(data_listx)))
else:
try:
buffer_item = data_listx[0:i]
del data_listx[0:i]
buffer_zuojiang = zuojiang(data_listx)
buffer_zuojiang += buffer_item
result.append(nitian( buffer_zuojiang))
except:
result.append("no")
if "yes" in result:
print("yes")
else:
print("no")
except:
print("no")
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。后续可能会有评论区,不过也可以在github联系我。