xray+rad 自动化edusrc
最近挖洞效率低下,学习了下扫描器
1.爬取漏洞平台上各大学校的网址
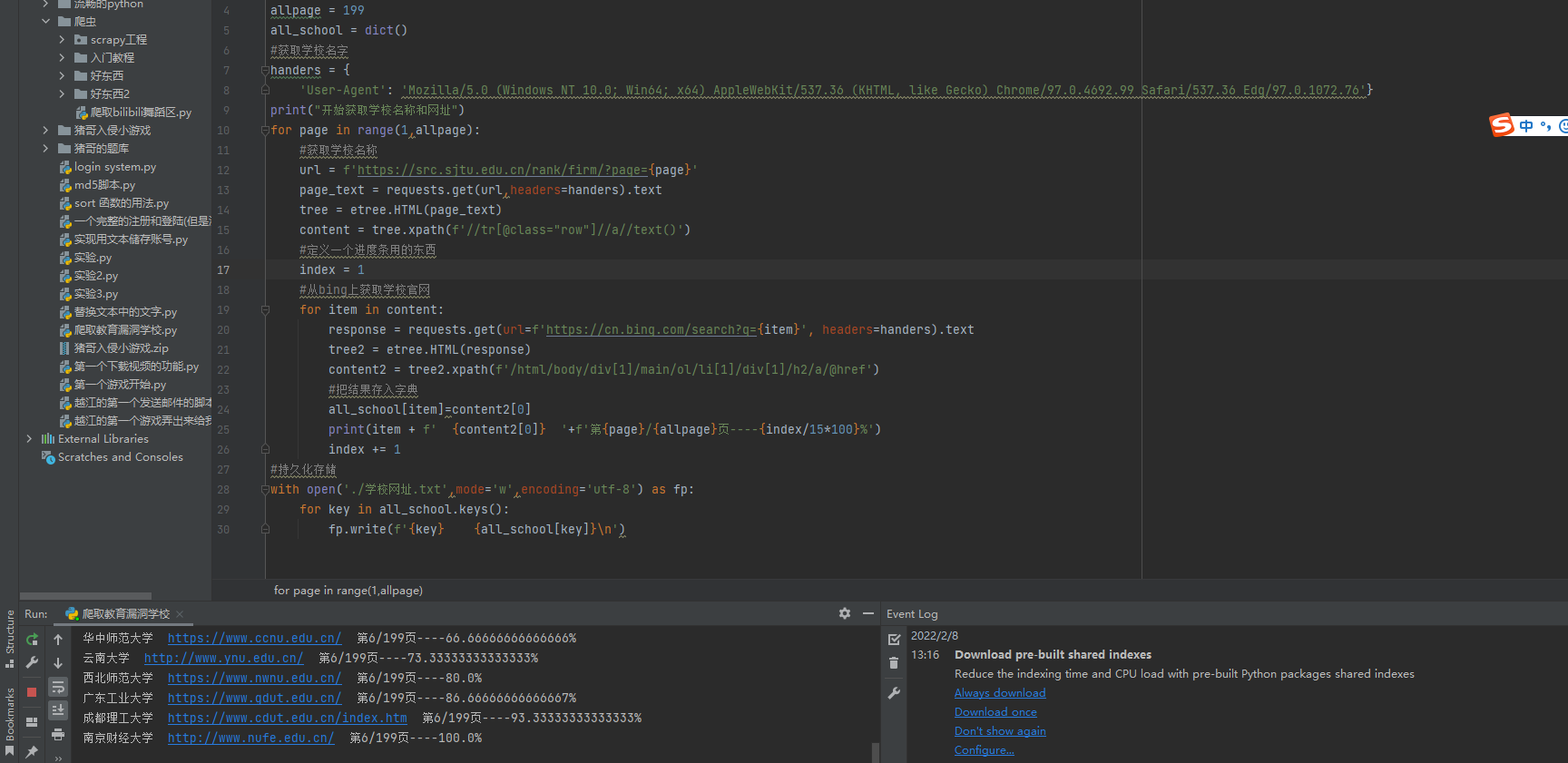
写了个小爬虫,有些会爬到百度百科里面,但是不影响,后面加个判断就好了。
import requests
import os
from lxml import etree
allpage = 199
all_school = dict()
#获取学校名字
handers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36 Edg/97.0.1072.76'}
print("开始获取学校名称和网址")
for page in range(1,allpage):
#获取学校名称
url = f'https://src.sjtu.edu.cn/rank/firm/?page={page}'
page_text = requests.get(url,headers=handers).text
tree = etree.HTML(page_text)
content = tree.xpath(f'//tr[@class="row"]//a//text()')
#定义一个进度条用的东西
index = 1
#从bing上获取学校官网
for item in content:
try:
response = requests.get(url=f'https://cn.bing.com/search?q={item}', headers=handers).text
tree2 = etree.HTML(response)
content2 = tree2.xpath(f'/html/body/div[1]/main/ol/li[1]/div[1]/h2/a/@href')
#把结果存入字典
all_school[item]=content2[0]
print(item + f' {content2[0]} '+f'第{page}/{allpage}页----{index/15*100}%')
index += 1
except:
print(f"{item}出错啦!")
index += 1
#持久化存储
with open('./学校网址.txt',mode='w',encoding='utf-8') as fp:
for key in all_school.keys():
fp.write(f'{key} {all_school[key]}\n')
#单独存储url方便扫描
with open('url.txt',mode='w',encoding='utf-8') as fp2:
for value in all_school.values():
fp2.write(f'{value}\n')
2.用xray和rad联动扫描url
工具是别人的
xray的被动扫描能力很强,但是主动扫描就弱了点,而rad的爬虫功能很强,所以将两种结合起来就能取长补短。但是它们两者不能进行批量检测。所以写了个脚本让两者结合进行批量检测。
首先将xray与rad所在文件夹加入到环境变量中,环境变量——用户变量——path——编辑

使用的是python3,安装依赖库
pip install pypiwin32
pip isntall requests
注意,系统需要装有chrome浏览器
之后将要扫描的目标放在url.txt文件中,一个目标一行。接着点击xray批量自动检测.bat
启动后如下,输入xray扫描后的漏洞文件名,然后rad框中输入任意的数字
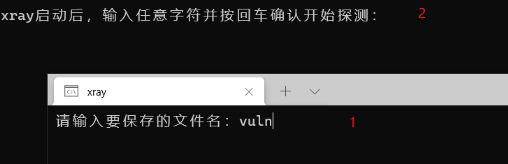
过程如下
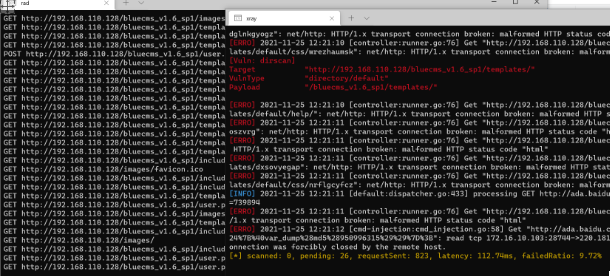
如果扫描出漏洞后会自动弹出浏览器漏洞报告
靶场测试
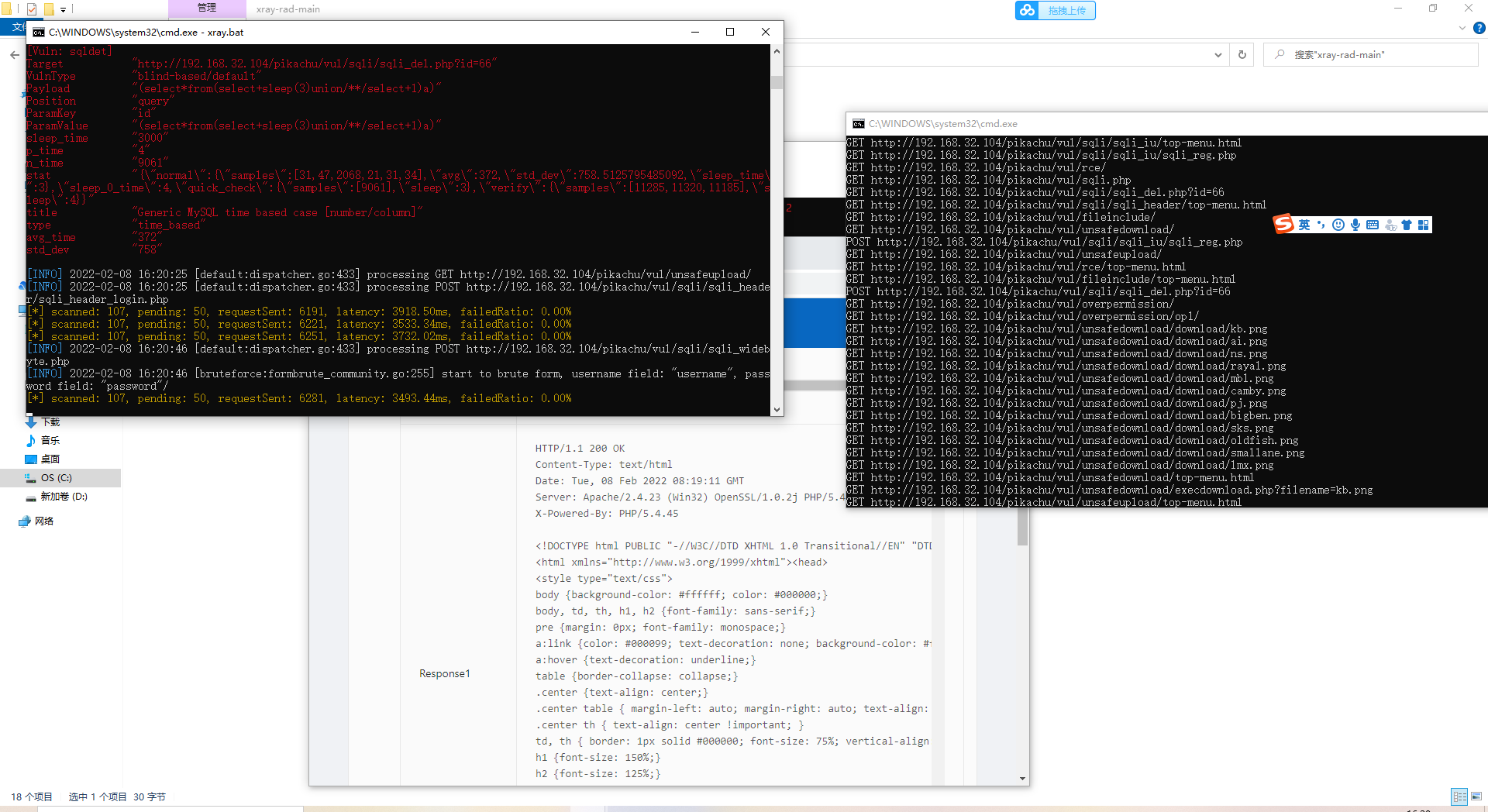
超!完美!
链接:https://pan.baidu.com/s/14pENeqIq-zAIvPgA92n9sw
提取码:flag{Favorite anime characters}
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。后续可能会有评论区,不过也可以在github联系我。